
下载的代码,30个epoch和300个epoch跑出来精度都差不多,是随机种子的问题吗?我该如何修改呢?

神经网络训练无论多少epoch精度都差不多是怎么回事儿

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


3条回答 默认 最新

 关注
关注- 这篇博客: 神经网络训练技巧中的 3 epoch 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
当一个完整的数据集通过了神经网络一次并且返回了一次,这个过程称为一次epoch。然而,当一个epoch对于计算机而言太庞大的时候,就需要把它分成多个小块 - batch。
为什么要使用多于一个epoch?
在神经网络中传递完整的数据集一次是不够的,而且我们需要将完整的数据集在同样的神经网络中传递多次。但请记住,我们使用的是有限的数据集,并且我们使用一个迭代过程即梯度下降来优化学习过程。如下图所示。因此仅仅更新一次或者说使用一个epoch是不够的。
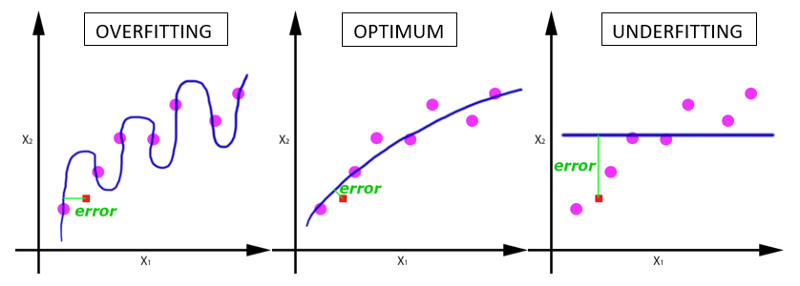
随着epoch数量增加,神经网络中的权重的更新次数也在增加,曲线从欠拟合变得过拟合.
那么,问题来了,几个epoch才是合适的呢?
不幸的是,这个问题并没有正确的答案。对于不同的数据集,答案是不一样的。但是数据的多样性会影响合适的epoch的数量。比如,只有黑色的猫的数据集,以及有各种颜色的猫的数据集。
如果随着Epoch的次数增加,准确度在一定时间内(比如5到10次)变化很小,就可以停止Epoch。开始时可以把Epoch次数设置的大一些,观察在哪个地方准确度变化很小,就把Epoch设置成几。也可以用早停法,防止过拟合。
4. 卷积滤波器和池化层大小
输入数据最好是2的整数幂次方,比如32(CIFAR-10中图片尺寸),64,224(ImageNet中常见的尺寸)。此外采用较小尺寸的滤波器(例3x3),小的步长(例1)和0值填充,不仅会减少参数数量,还会提升整个网络的准确率。当用3x3的滤波器,步长为1,填充(pad)为1时,会保持图片或特征图的空间尺寸不变。池化层经常用的池化大小是2x2。
5. 在预训练的模型上微调
很多state-of-the-arts deep networks的模型被开源出来,这些预训练的模型泛化能力(generalization abilities)很强,因此可以在这些模型的基础上根据自己的任务微调。微调涉及两个重要的因素:新数据集的大小和两个数据集的相似度。网络顶层特征包含更多dataset-specific特征。
数据集相似性高 数据集相似性低 数据少 直接提取顶层特征来训练线性分类器 比较困难,尝试用不同层的特征训练一个线性分类器 数据多 用较小的学习率微调更多的层 用较小的学习率微调尽可能多的层
本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 分享- 这篇博客: 神经网络训练技巧中的 3 epoch 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
- 2023-03-01 09:04回答 3 已采纳 这篇博客: 神经网络训练技巧中的 3 epoch 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读: 当一个完整的数据集通过了神经网络一次并且返回了一次,这个过程称为一次epoch
- 2023-02-18 15:36回答 2 已采纳 基于Monster 组和GPT的调写:使用torch.cuda.empty_cache()函数手动释放显存。如果想要在每个epoch的训练结束后释放训练集显存,可以在每个epoch结束时调用该函数。
- 回答 1 已采纳 现象很正常啊,遇到陌生的数据损失肯定会高,loss肯定是在震荡但整体呈下降趋势的
- 2021-08-26 11:34小白学视觉的博客 33条神经网络训练秘技,trick 合集 3。 26秒单GPU训练CIFAR10,工程实践。 Batch Normalization,虽然玄学,但是养活了很多炼丹师。 Searching for Activation Functions,swish 激活函数。 炼丹是玄学还是科学?我...
- 2022-03-24 03:18
 paddle 卷积神经网络训练时报错InvalidArgumentError: The input tensor X of SumOp must have same shape..
paddle
深度学习
神经网络
回答 1 已采纳 你传入的张量是252,2但需要的是21,2考虑使用reshape把维度变化一下飞桨的框架我没用过,pytorch是这么操作的,你搜一搜类似的改变张量shape的函数
paddle 卷积神经网络训练时报错InvalidArgumentError: The input tensor X of SumOp must have same shape..
paddle
深度学习
神经网络
回答 1 已采纳 你传入的张量是252,2但需要的是21,2考虑使用reshape把维度变化一下飞桨的框架我没用过,pytorch是这么操作的,你搜一搜类似的改变张量shape的函数 - 2022-09-05 14:20回答 1 已采纳 a=b()(x)这看起来很怪吗如果你知道函数b的返回值是一个函数,像这样def b(): def c(): ... return c还怪吗b(),其实就是cb()(x)其实就是c(x
- 2021-04-05 20:56回答 2 已采纳 mmdetection没试过,但是yolov5默认300多次是因为人家是在coco数据集上面训练的,而你看yolov5的主页,里面的各个模型的对比可以看出来,基本上都是300epoch的时候达到较好的
- 2021-08-21 11:00风度78的博客 33条神经网络训练秘技,trick 合集 3。 26秒单GPU训练CIFAR10,工程实践。 Batch Normalization,虽然玄学,但是养活了很多炼丹师。 Searching for Activation Functions,swish 激活函数。 炼丹是玄学还是科学?我...
- 2020-04-22 11:00回答 2 已采纳 您好,这个问题是什么原因呢?我也遇到了同样的问题
- 2021-04-03 13:35回答 1 已采纳 问题分析: 很有可能是过拟合了! 解决方案: (1)增加Dropout,随机断开神经网络之间的连接,减少每次训练时实际参与计算的模型的参数量,从而减少了模型的实际容量,来防止过拟合。 (
- 2019-09-06 17:29回答 1 已采纳 print(sess.run(cost),feed_dict=feeds_train) 你把数据喂到了外边 在cost后加逗号,然后接喂的数据
- 2021-09-16 14:00机器学习与AI生成创作的博客 点击上方“机器学习与生成对抗网络”,关注星标获取有趣、好玩的前沿干货!https://www.zhihu.com/question/330766768编辑:机器学习算法与知识图谱声明:仅做...
- 2022-03-02 23:40回答 1 已采纳 有个简单的办法,提前打开任务管理器翻到GPU那一栏,在训练或者预测数据的时候观察各项指标特别是复制有没有起伏
- 2021-10-17 18:01SophiaCV的博客 点上方计算机视觉联盟获取更多干货 仅作学术分享,不代表本公众号立场,侵权联系删除 转载于:作者丨叶润源 来源丨https://www.yuque.com/yerunyuan/ar9831/tsm0id#Kfi4w 编辑丨极市平台 985人工智能博士笔记推荐 ...
- 2023-12-31 21:35囚生CY的博客 以及5区的区间新被两次刷新(山神降临),10年7冠,重回王座,往路3个区间赏,1个区间新,也算是第100回箱根驿传之圆满,要知道复路的7区天降暴雨,极其恶劣的条件下都刷新大会记录,抛开民族情节不谈,小日本真的令...
- 2020-04-21 23:03AI算法修炼营的博客 点击上方“AI算法修炼营”,选择加星标或“置顶”标题以下,全是干货来源:https://www.zhihu.com/question/41631631编辑:公众号@深度学习与计算机视觉声...
- 2021-06-04 00:47人工智能与算法学习的博客 0 摘要transformer结构是google在17年的Attention Is All You Need论文中提出,在NLP的多个任务上取得了非常好的效果,可以说目前NLP发展都离不开...
- 2019-09-04 10:50元气少女缘结神的博客 我询问了前一篇我提到很推崇的那个博主学习tensorflow的方法,他是先看书籍《深度学习之Tensorflow入门原理与进阶实战》,然后再看MOOC上北京大学曹健老师的《人工智能实践:tensorflow笔记》视频课程,每看完书的一...
- 2018-01-02 19:29莉莉兹的博客 至于竞赛方面,知乎“看山杯”最后,获奖队伍都使用了深度神经网络。比赛群里官方人员也明确说了,传统方法可能不行,你们最好考虑 Deep Learning。 开赛一段时间后,官方给出了一个 word2vec + fasttext 的...
- 没有解决我的问题, 去提问

问题事件
 系统已结题
3月15日
系统已结题
3月15日 已采纳回答
3月7日
已采纳回答
3月7日-
创建了问题
3月1日
悬赏问题
- ¥15 用windows做服务的同志有吗
- ¥60 求一个简单的网页(标签-安全|关键词-上传)
- ¥35 lstm时间序列共享单车预测,loss值优化,参数优化算法
- ¥15 Python中的request,如何使用ssr节点,通过代理requests网页。本人在泰国,需要用大陆ip才能玩网页游戏,合法合规。
- ¥100 为什么这个恒流源电路不能恒流?
- ¥15 有偿求跨组件数据流路径图
- ¥15 写一个方法checkPerson,入参实体类Person,出参布尔值
- ¥15 我想咨询一下路面纹理三维点云数据处理的一些问题,上传的坐标文件里是怎么对无序点进行编号的,以及xy坐标在处理的时候是进行整体模型分片处理的吗
- ¥15 一直显示正在等待HID—ISP
- ¥15 Python turtle 画图